

闲言
也是服了到现在还没出成绩,截止到现在周六下午六点依旧没有公告,没有复试名单,虽然知道自己大差不差但是一切没有尘埃落定还是心里不踏实。
阿里云今天看了下有一个38块钱一年的2核2G 200M带宽 40G机械的云服务器,不过需要抢,哎呀我去没抢到气死我了,绑定个身份的功夫就没了服了也是。看了下规则,每天上午十点和下午三点可以购买,要求新用户。行吧,ok,明天试试也许可以。
回归:线性回归用于预测数值,因变量是连续值,根据样本点分布得出函数,如房价和平米数的关系;逻辑回归用于分类,因变量是离散值
分类:将样本按照类别区分开,让机器进行学习其特点,用于有监督学习有标签Yi
聚类:用于无监督学习,将特征类似的样本划在一起。
学习准则:让模型知道学的好不好——损失函数来衡量(预测值和真实值的差),优化来降低损失函数
期望风险未知,经验风险通过训练来得出,要降低风险到最小,最优化问题——梯度下降法
随机梯度下降是每个样本都计算
参数是模型学出来的,超参数是人为给的,学习率是超参数
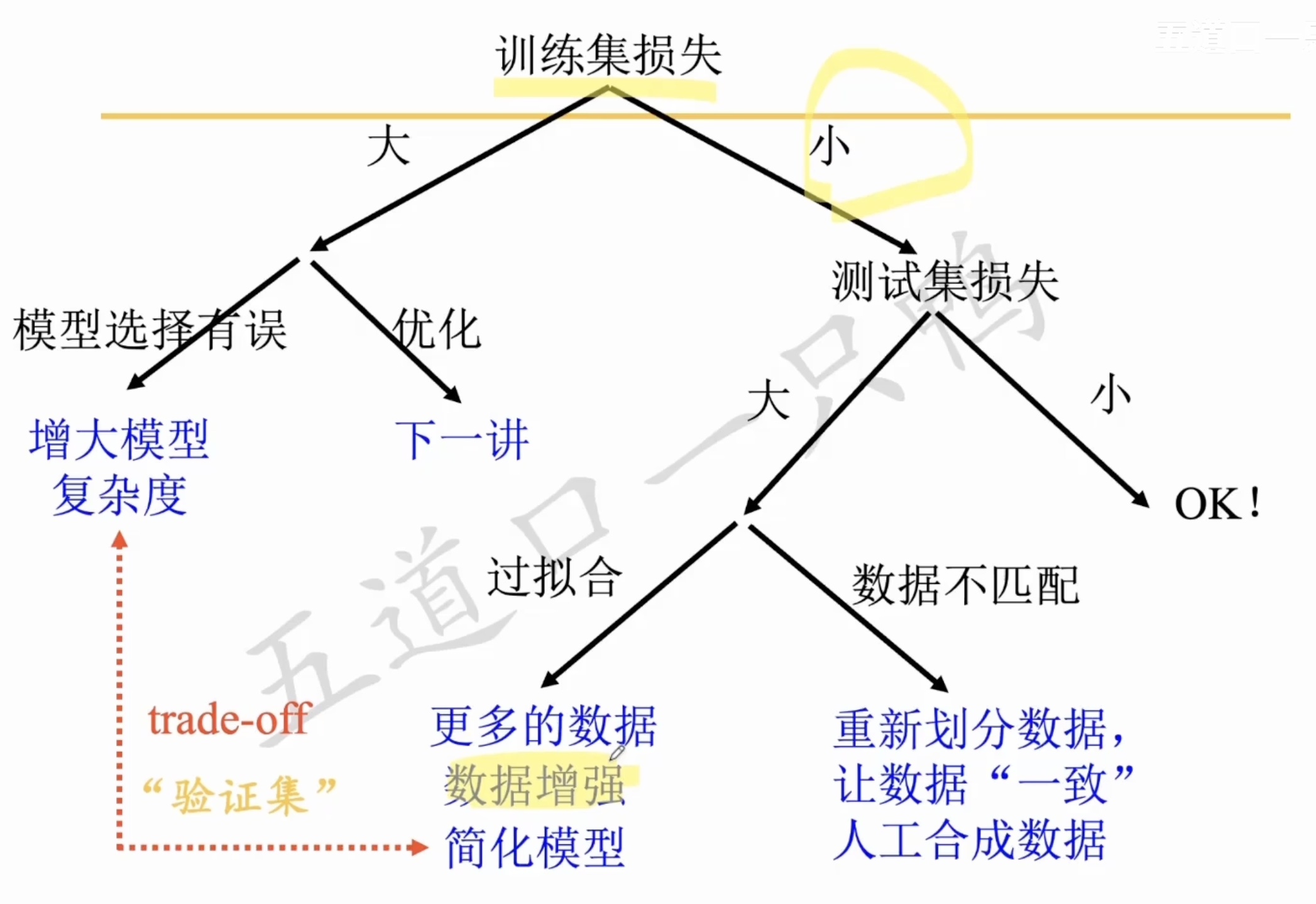
过拟合(overfitting)经验风险最小化原则会导致模型在训练集上错误率很低但在测试集上错误率很高,往往是由于训练数据少和噪声等原因造成的。
避免过拟合的方法:正则化、交叉验证、减少特征数量。
泛化错误:期望风险(真实)和经验风险(训练集)不相等
偏差—方差分解:偏差模型预测的平均值和真实值之间的差距,偏差高可能欠拟合;方差模型对于不同训练集预测结果的变化程度,方差高可能过拟合。噪声随机误差
泛化误差:真实情况下模型的误差。=【偏差的平方+方差+噪声】

正则化——降低模型复杂度,所有损害优化的方法,增加优化约束,干扰优化过程
三个定理:
没有免费午餐定理——对于基于迭代的最优化算法没有算法对所有问题都有效
丑小鸭定理(北京大学定理):从不同角度得到的相似度不同,相似度定义多种多样
奥卡姆剃刀原理——模型尽量简单,如无必要,勿增实体,熵(事件混乱程度)小
机器学习步骤:

软件测试的目的是发现软件中的错误和缺陷,提高软件质量和可靠性,保证软件能够满足客户的需求和期望。
事务的隔离级别:读未提交、读已提交、可重复度和串行化。这些隔离级别决定了事务之间对数据的并发访问和控制程度。
敏捷开发:是一种软件开发方法,核心是快速迭代和持续改进。在敏捷开发中,开发团队会将项目分解成多个小的迭代,每个迭代都包含了从需求分析、设计、开发、测试到部署的整个过程。
决策树:是一种树形结构的分类器,他通过的训练数据的学习,构建一颗决策树,用于对新数据进行分类预测。决策树的每个节点表示一个特征或属性,每个分支表示一个决策规则,每个叶子结点表示一个类别或预测结果。
随机森林:是一种集成学习方法,他通过构建多个决策树来提高模型的准确性和泛化能力。
软件设计模式:针对反复出现的问题总结归纳出的通用解决方案,有单例模式、工厂模式、观察者模式。